


Con el movimiento DevOps en el centro de atención, cada vez más desarrolladores se preocupan por la entrega de aplicaciones web de extremo a extremo. Esto incluye la implementación, el rendimiento y el mantenimiento de la aplicación.
A medida que una aplicación gana más usuarios en un entorno de producción, es cada vez más importante que usted entienda la función del servidor. Para determinar la salud de sus aplicaciones, necesita reunir métricas de rendimiento para los servidores que ejecutan sus aplicaciones web.
Todos los diferentes tipos de servidores web (por ejemplo, Apache, IIS, Azure, AWS y NGINX) tienen métricas de rendimiento de servidor similares. La mayor parte de mi experiencia en este ámbito reside en Microsoft Azure, que proporciona una interfaz fácil de usar para buscar y recopilar datos. Trabajar con Microsoft Azure ofrece la capacidad de hospedar aplicaciones en los Servicios de aplicaciones de Azure (PaaS) o en Máquinas virtuales de Azure (IaaS). Esta configuración le permite ver las diferentes métricas de la aplicación o el servidor en ejecución.
Debido a toda esta experiencia que he tenido en los últimos meses, he encontrado lo que creo que es ocho de las métricas de rendimiento del servidor más útiles. Estas métricas se pueden dividir en dos categorías: métricas de rendimiento de la aplicación y métricas de experiencia del usuario.
Comencemos mirando las métricas bajo el paraguas de rendimiento de la aplicación .
Métricas de rendimiento de la aplicación
Las métricas de rendimiento de la aplicación son específicas de la velocidad de las aplicaciones web que se ejecutan. Si tiene problemas con una aplicación que funciona lentamente, estas métricas son un buen lugar para comenzar.
Métrica 1: Solicitudes por segundo
Las solicitudes por segundo (también llamado rendimiento) es como suena: es la cantidad de solicitudes que recibe su servidor cada segundo. Esta es una métrica fundamental que mide el propósito principal de un servidor web, que es recibir y procesar solicitudes. Las aplicaciones a gran escala pueden alcanzar hasta 2,000 solicitudes por segundo.
Dada la suficiente carga, cualquier servidor puede caerse. Al considerar el impacto, recuerde que las solicitudes son solo eso: una única solicitud al servidor. Esta métrica no considera lo que está sucediendo en cada una de estas solicitudes.
Esto nos lleva a nuestra siguiente métrica.
Métrica 2: Entrada y salida de datos
La siguiente métrica que sugiero que mire es su información de entrada y salida . Los datos enmétrica son el tamaño de la carga útil de solicitud que va al servidor web. Para esta métrica, una tasa más baja es mejor (menor significa que las cargas útiles pequeñas se envían al servidor). Un alto nivel de datos en la medición puede indicar que la aplicación está solicitando más información de la que necesita.
La salida de datos es la carga útil de respuesta que se envía a los clientes. A medida que los sitios web se hacen más grandes con el tiempo , esto causa un problema especialmente para aquellos con conexiones de red más lentas. Las cargas útiles de respuesta exageradas conducen a sitios web lentos, y los sitios web lentos no satisfarán a sus usuarios. Con suficiente lentitud, estos usuarios abandonan el sitio web y siguen adelante. Google sugiere que las páginas que demoran tres o más segundos para que los usuarios móviles se carguen tienen un 53% de probabilidad de que los usuarios abandonen antes de que se complete la carga.
Métrica 3: Tiempo de respuesta promedio
Definido directamente, el tiempo de respuesta promedio (ART) es el tiempo promedio que toma el servidor para responder a todas las solicitudes que se le dan. Esta métrica es un indicador sólido del rendimiento general de la aplicación, dando una impresión de la usabilidad de la aplicación. En general, cuanto más bajo sea este número, mejor. Pero hay estudios que muestran que el límite máximo para un usuario que navega por una aplicación es de alrededor de un segundo.
Al considerar el tratamiento de TAR, recuerde lo que significa el acrónimo: es solo un promedio. Al igual que todas las métricas determinadas con un promedio, los valores atípicos altos pueden eliminar el número por completo y hacer que el sistema parezca más lento de lo que es. ART es más útil cuando se usa junto con nuestra próxima métrica en la lista.
Métrica 4: tiempo máximo de respuesta
Similar al tiempo de respuesta promedio, el tiempo de respuesta máximo (PRT) es la medición de las respuestas más largas para todas las solicitudes que llegan a través del servidor. Este es un buen indicador de los puntos de dolor de rendimiento en la aplicación. PRT no solo le dará una idea de qué partes de sus aplicaciones están causando bloqueos; También te ayudará a encontrar la causa raíz de estos problemas. Por ejemplo, si hay una cierta página web lenta o una llamada particularmente lenta, esta métrica puede darle una idea de dónde buscar.
Métrica 5: Utilización de hardware
A continuación, vamos a hablar sobre la utilización general del hardware. Cualquier aplicación o servidor en ejecución está limitado por los recursos asignados a él. Por lo tanto, hacer un seguimiento de la utilización de los recursos es clave, principalmente para determinar si existe un cuello de botella en los recursos. Tienes que considerar tres aspectos principales de un servidor:
- El procesador
- La memoria RAM (memoria)
- El espacio en disco y el uso.
Al considerar esto, está buscando lo que puede convertirse en un cuello de botella para todo el sistema. Como lo mostrará cualquier computadora física (o virtual) que se ejecute con estos componentes, el rendimiento es tan fuerte como su enlace más débil. Esta métrica puede indicarle qué es el cuello de botella y qué componente físico se puede actualizar para mejorar el rendimiento.
Por ejemplo, puede tener problemas al tratar de representar datos desde un disco duro físico. Esto causará un cuello de botella en las interacciones de E / S entre la recopilación de archivos y su presentación al usuario. Mientras el disco duro gira y recopila datos, los otros componentes físicos no hacen nada. Una actualización a una unidad de estado sólido mejoraría el rendimiento de toda la aplicación porque el cuello de botella desaparecerá.
Métrica 6: Recuento de hilos
La siguiente métrica, el número de subprocesos de un servidor, le indica cuántas solicitudes simultáneas están sucediendo en el servidor en un momento determinado. Esta métrica le ayudará a comprender cómo se ve la carga general de un servidor desde un nivel de solicitud. También le dará una idea de la carga colocada en el servidor cuando se ejecutan varios subprocesos.
Por lo general, un servidor se puede configurar con un número máximo de subprocesos permitido. Al hacer esto, está configurando un límite máximo de solicitudes que pueden suceder al mismo tiempo. Si el número de hilos supera este valor máximo, todas las solicitudes restantes se diferirán hasta que haya espacio disponible en la cola para procesarlos. Si estas solicitudes diferidas tardan demasiado tiempo, generalmente expiran.
Vale la pena señalar que aumentar el número máximo de subprocesos generalmente se basa en tener los recursos adecuados disponibles para su uso.
Métricas de experiencia de usuario
Ahora que hemos cubierto las métricas de rendimiento de la aplicación, analicemos algunas que están centradas en la experiencia del usuario. Estas métricas de rendimiento del servidor pueden medir la satisfacción general de sus usuarios al usar sus aplicaciones web.
Métrica 7: Uptime
Aunque no está directamente relacionado con su rendimiento, el tiempo de actividad del servidor es una métrica crítica. El tiempo de actividad es el porcentaje que el servidor está disponible para su uso. Lo ideal es apuntar a un tiempo de actividad del 100%, y verá muchos casos de tiempo de actividad del 99,9% (o más) al mirar los paquetes de alojamiento web. No es infrecuente que los proyectos de software cumplan con un acuerdo de nivel de servicio que dicta una tasa particular de tiempo de actividad del servidor. Si la comprobación de las métricas de tiempo de actividad no es algo que su servidor pueda proporcionar, hay muchos servicios de terceros, como Updown.io , que pueden hacerlo por usted. Estos servicios pueden incluso darle una descripción visual de su informe:
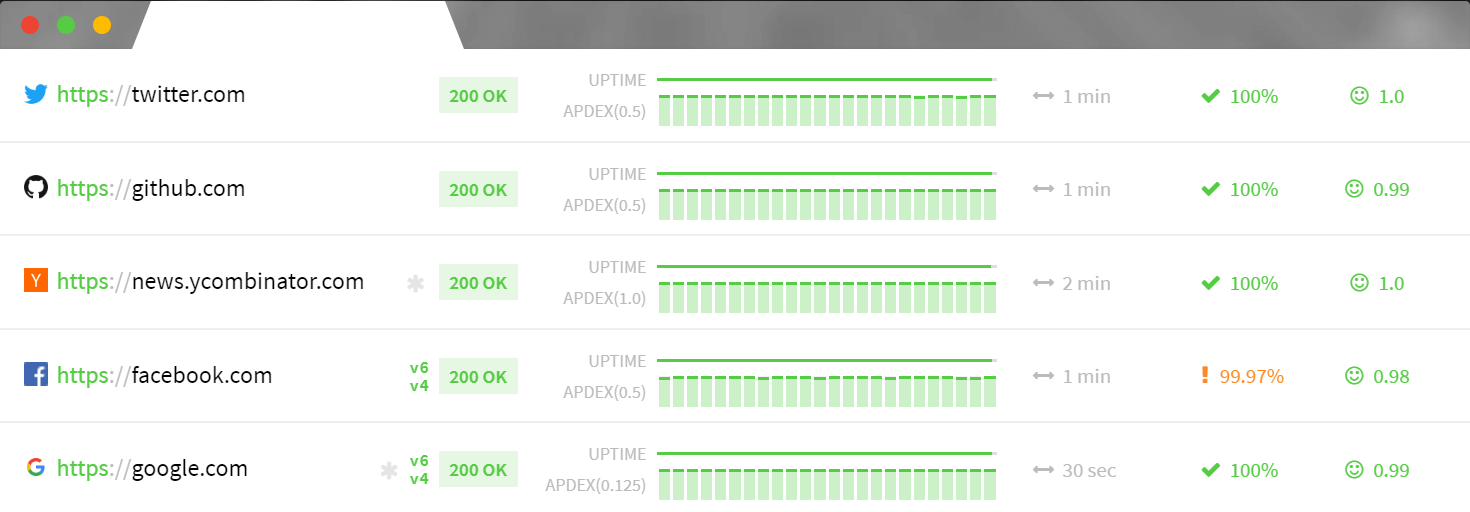
Y he aquí un dato interesante. Cálculo del tiempo de inactividad mensual permitido muestra:
- 99%: ~ 7 horas
- 99.9%: ~ 45 minutos
- 99.999%: 30 segundos
Métrica 8: tasa de error del servidor HTTP
La tasa de error del servidor HTTP es una métrica de rendimiento que no se relaciona directamente con el rendimiento de la aplicación, pero es muy crítica. Devuelve el recuento de errores internos del servidor (o códigos HTTP 5xx) que se devuelven a los clientes. Estos errores son devueltos por las aplicaciones que no funcionan correctamente cuando tiene una excepción u otro error que no se está manejando correctamente. Una buena práctica es configurar una alerta cada vez que se producen este tipo de errores. Debido a que 500 errores son casi completamente evitables, puede estar seguro de que tiene una aplicación robusta. Ser notificado de todos los errores del servidor HTTP le permite estar al tanto de cualquier error que ocurra. Esto evita el problema de tener errores acumulados en la aplicación a lo largo del tiempo.
Cómo medir el rendimiento del servidor
Medir el rendimiento del servidor con una herramienta Application Performance Monitoring (APM) como Raygun APM es la forma más fácil y precisa de medir la salud de su software. APM le dará a su equipo un mayor contexto en sus mayores preguntas sobre el rendimiento de la aplicación al proporcionar visualizaciones en métricas, como solicitudes por segundo y más. La siguiente captura de pantalla muestra el diagrama de llamas de Raygun APM mostrando un error y su ubicación en el código.
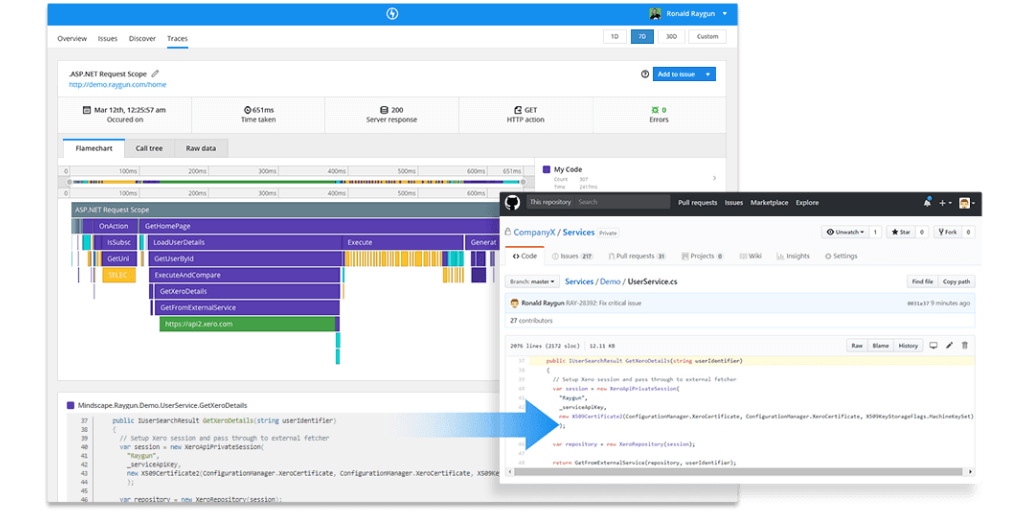
Mantenga su dedo en el pulso
Estas son las métricas de rendimiento del servidor que personalmente he encontrado las más valiosas. Si recopila y supervisa este tipo de datos tanto de la experiencia de sus usuarios como del rendimiento de su aplicación, muy poco caerá entre las grietas.
¿Mencioné alguna métrica que no esté usando actualmente? Considera probarlos. Después de todo, las métricas son su mejor manera de controlar el rendimiento de su servidor y, por extensión, el estado de su aplicación.
0 Comentarios